
SPARKLE e Intel: Potenciando la Inteligencia Artificial con Soluciones de Servidor y VRAM de Alta Capacidad
SPARKLE, en colaboración con Intel, presenta una robusta gama de soluciones de hardware diseñadas específicamente para satisfacer las exigentes demandas de las cargas de trabajo de IA, desde la inferencia local hasta las aplicaciones empresariales a gran escala. La propuesta se centra en ofrecer sistemas multi-GPU con una VRAM masiva, posicionándose como una alternativa costo-eficiente para tareas como el fine-tuning de modelos de lenguaje (LLMs) y la creación de aplicaciones de RAG (Generación Aumentada por Recuperación) multimodales.
Está impulsado por procesadores duales Intel Xeon Scalable de 4ta o 5ta generación y cuenta con 32 ranuras de memoria DDR5, lo que garantiza un rendimiento excepcional para las tareas más intensivas. La arquitectura está optimizada para la comunicación directa entre CPU y GPU a través de tecnologías como PCIe Direct Drive y tarjetas de extensión PCIe 5.0, minimizando la latencia y maximizando el ancho de banda, un factor crucial para el entrenamiento y la inferencia de grandes modelos.

El producto estrella de esta línea es el servidor C741-6U-Dual 16P, una potente máquina diseñada para alcanzar una capacidad máxima de 768GB de VRAM. Este servidor, montado en un chasis de 6U, logra esta impresionante cifra al integrar hasta dieciséis tarjetas gráficas SPARKLE Intel® Arc™ Pro B60 Duo de 48GB.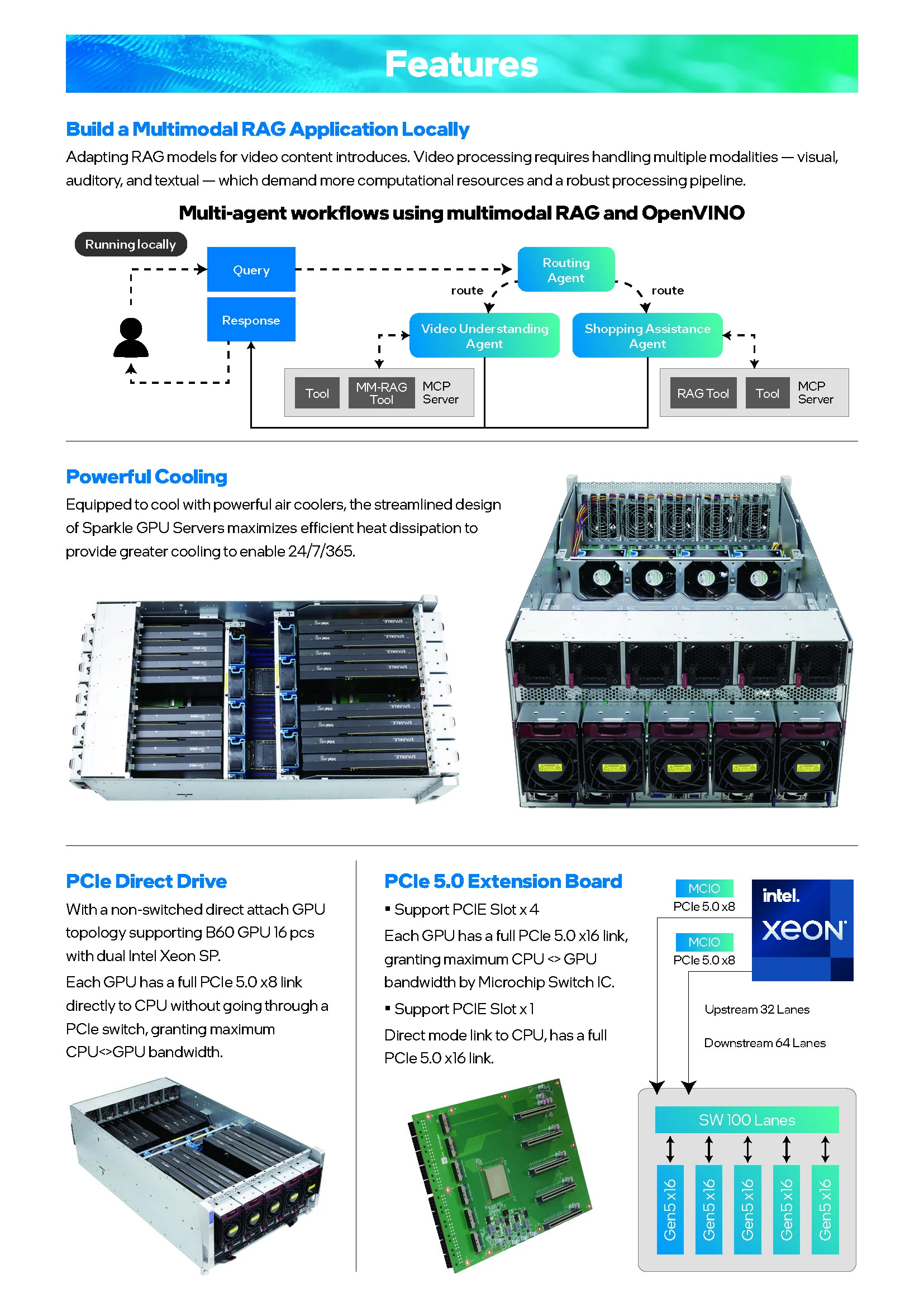
¿Cómo funciona el Switch? Esta tarjeta toma un gran número de carriles PCIe que vienen del procesador (en el diagrama, "Upstream 32 Lanes") y utiliza un chip especializado llamado "Microchip Switch IC" para gestionar y multiplicar esos carriles hacia las GPUs (en el diagrama, "Downstream 64 Lanes").
¿Cómo Funciona un Switch PCIe?
Imagina que la CPU es el director de orquesta y las 16 GPUs son los músicos. El director no puede hablar con cada músico a la vez; necesita un sistema para distribuir las partituras (los datos) de forma eficiente. Aquí es donde entra el switch.
-
Recibe Datos: El switch recibe un gran "paquete" de datos desde la CPU a través de una conexión de alta velocidad (los carriles o "lanes" PCIe de entrada).
-
Lee la Dirección: Cada paquete de datos tiene una "dirección de destino", que le dice a qué GPU específica debe ir. El switch lee esta dirección a una velocidad vertiginosa.
-
Conmutación (Switching): De forma inteligente, el chip crea una ruta temporal y directa para enviar ese paquete de datos exclusivamente a la GPU correcta, sin que los demás se enteren. Esto es similar a cómo un conmutador de red envía datos solo al ordenador que los solicitó, y no a todos los de la red.
-
Manejo de Múltiples Peticiones: Su verdadera magia es que puede hacer esto para múltiples GPUs simultáneamente. Gestiona el tráfico para evitar colisiones y cuellos de botella, asegurando que el flujo de datos sea constante y eficiente.
Recordemos que en cargas de trabajo enfocadas a la Inteligencia Artificial, es mucho más facil cargar y distribuir un modelo a través de múltiples GPUs, debido a que la latencia es substancialmente menos crucial que en otras aplicaciones, como por ejemplo: El gaming, donde recordemos que tiene mucho tiempo que no vemos configuraciones con múltiples núcleos en una misma tarjeta.







Comentarios
Aún no hay comentarios. ¡Sé el primero en comentar!